
























Deepseek-R1 14B on Ollama: Best Performance Tests of GPU Servers
Deepseek-R1:14B is a powerful open-source LLM (Large Language Model) that has gained traction for its efficiency and strong performance across various AI applications. Running it on Ollama 0.5.7, a popular framework for LLM inference, requires choosing the right GPU for optimal speed and cost-effectiveness.
This article explores Deepseek-R1:14B's performance benchmarks on different GPUs, evaluates the best hardware configurations, and provides recommendations for server setups. Keywords covered include Deepseek-R1:14B benchmark, best GPU for LLM inference, AI model server setup, Deepseek-R1:14B Ollama performance, and Deepseek-R1:14B GPU comparison.
Deepseek-R1:14B Benchmark on Different GPUs
| GPU Servers | A4000 | P100 | V100 | A5000 | RTX4090 |
|---|---|---|---|---|---|
| GPU Details | CUDA Cores: 6144 Tensor Cores: 192 GPU Memory: 16GB | CUDA Cores: 3584 GPU Memory: 16GB | CUDA Cores: 5120 Tensor Cores: 640 GPU Memory: 16GB | CUDA Cores: 8192 Tensor Cores: 256 GPU Memory: 24GB | CUDA Cores: 16384 Tensor Cores: 512 GPU Memory: 24GB |
| Platform | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 |
| Model | Deepseek-R1, 14b, 9GB, Q4 | Deepseek-R1, 14b, 9GB, Q4 | Deepseek-R1, 14b, 9GB, Q4 | Deepseek-R1, 14b, 9GB, Q4 | Deepseek-R1, 14b, 9GB, Q4 |
| Downloading Speed(MB/s) | 36 | 11 | 11 | 11 | 11 |
| CPU Rate | 3% | 2.5% | 3% | 3% | 2% |
| RAM Rate | 6% | 6% | 5% | 6% | 3% |
| GPU UTL | 88% | 91% | 80% | 95% | 95% |
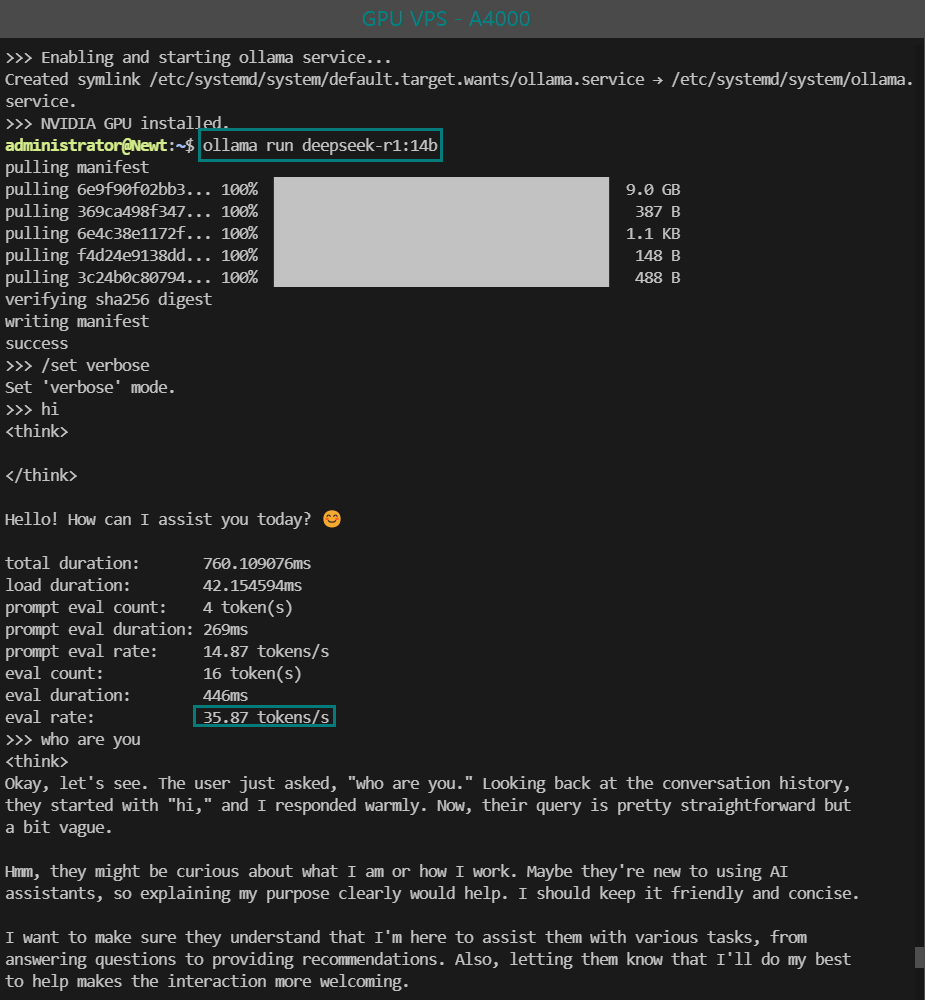
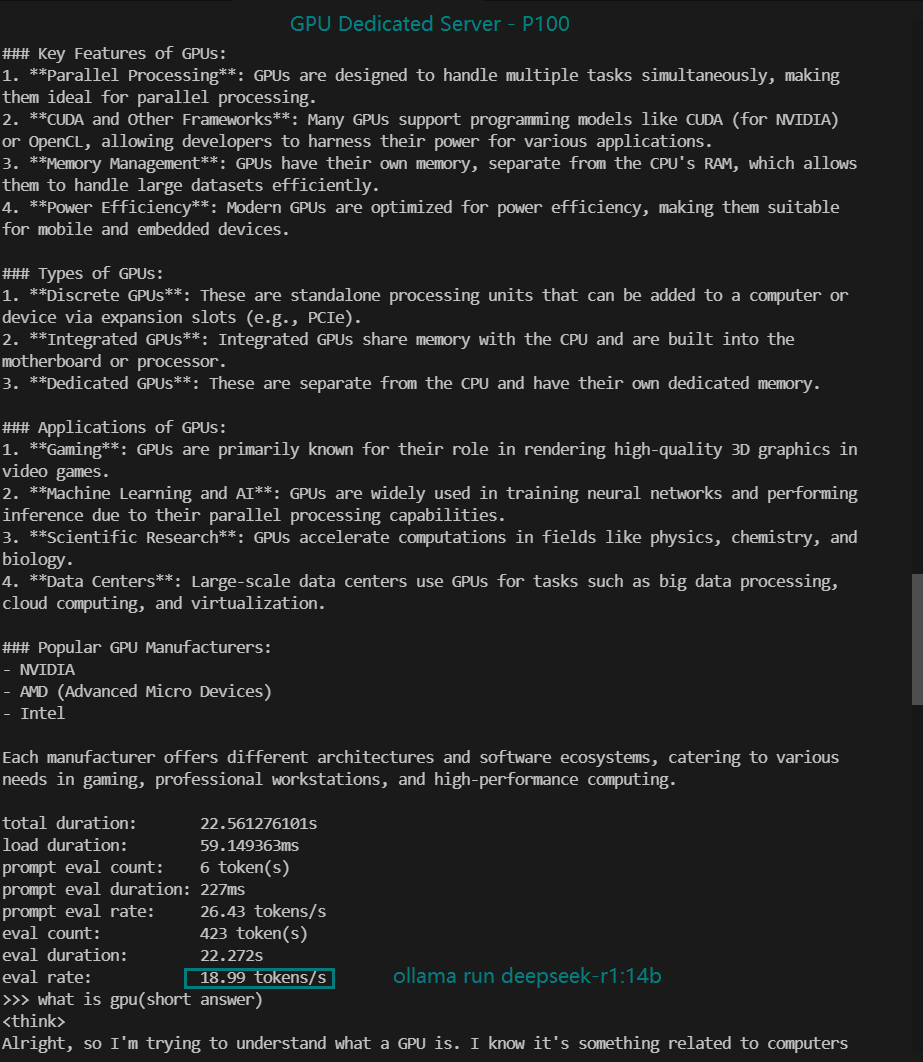
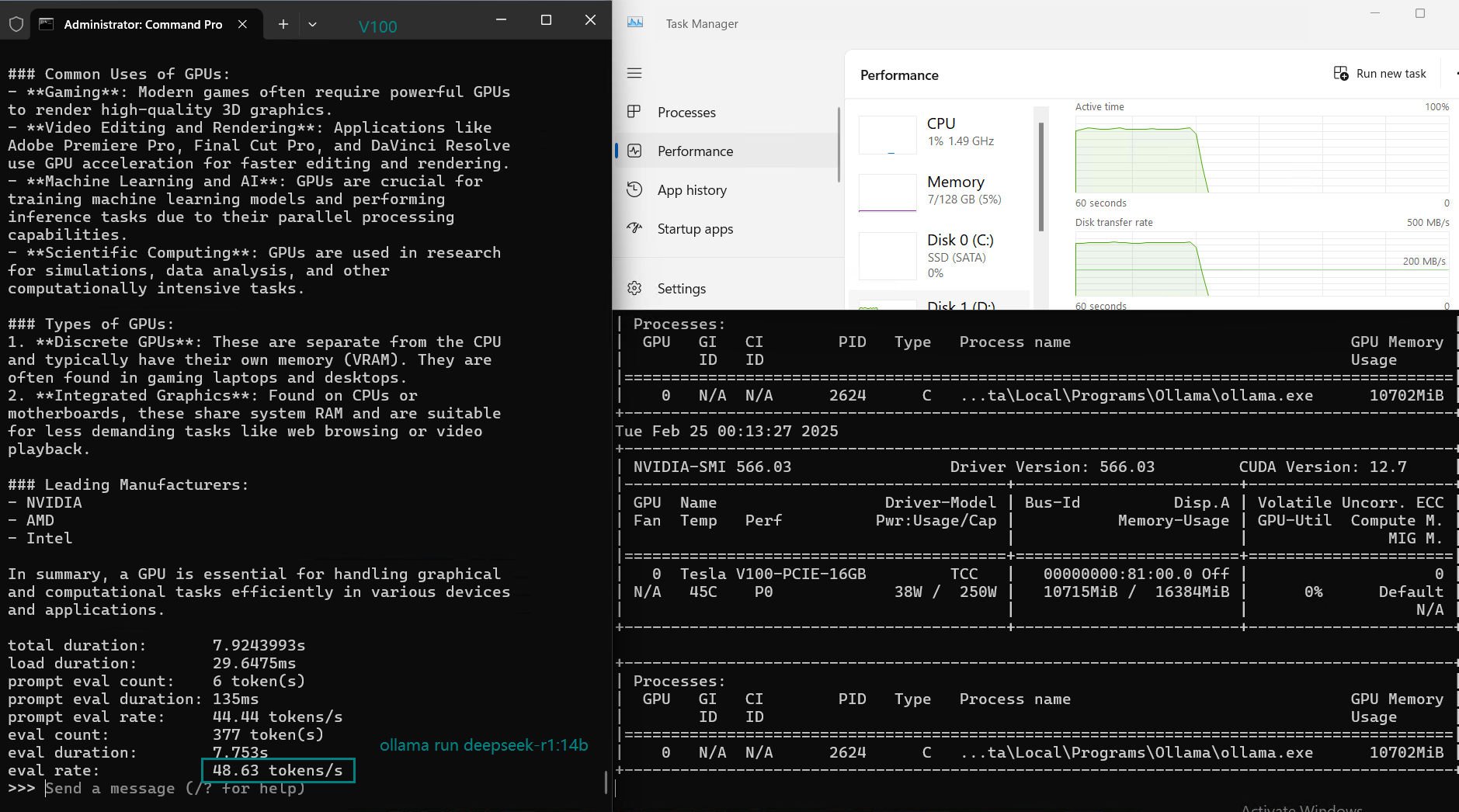
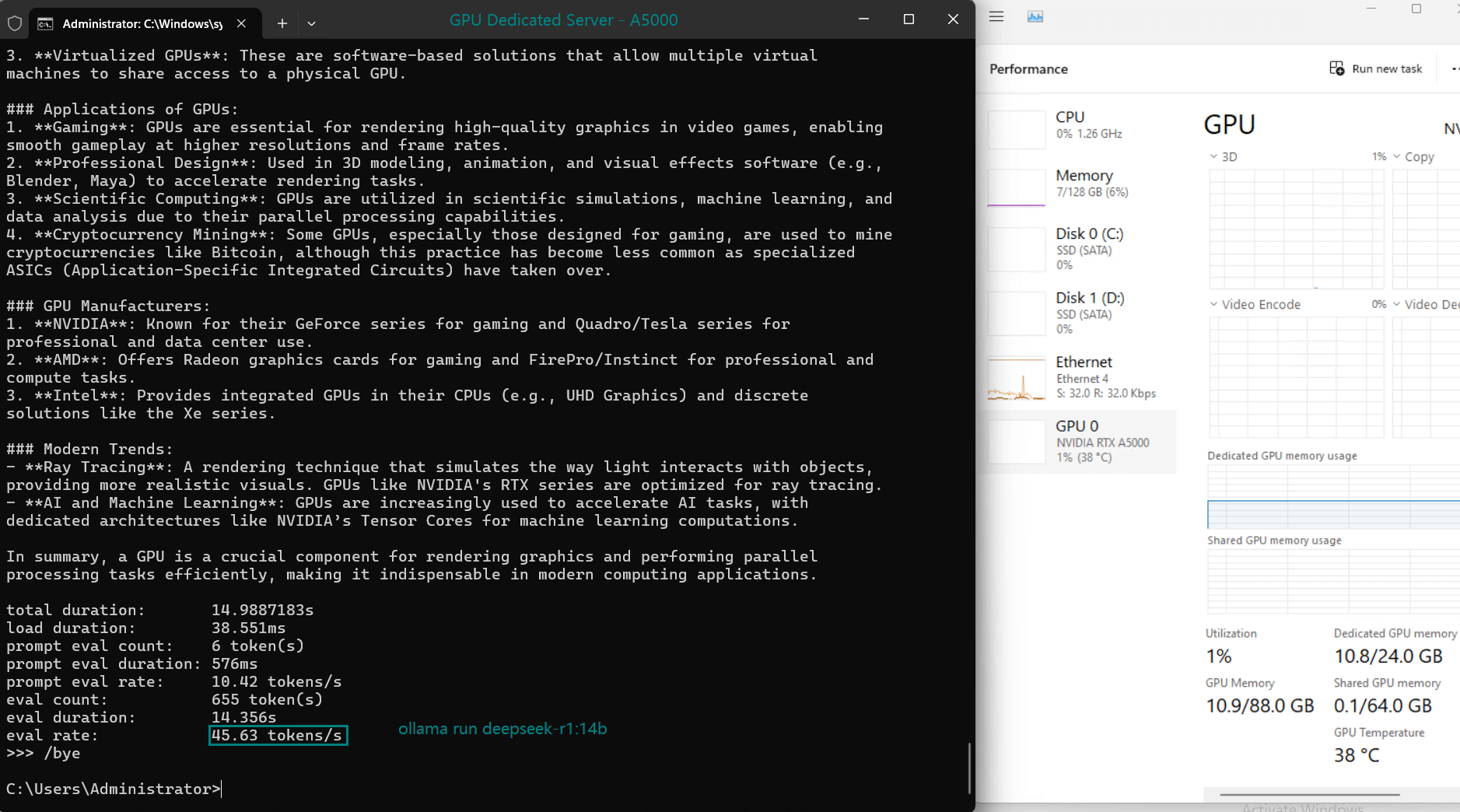
| Eval Rate(tokens/s) | 35.87 | 18.99 | 48.63 | 45.63 | 58.62 |
Key Takeaways:
- RTX 4090 is the fastest performer, achieving 58.62 tokens/s, making it the best consumer-grade GPU for Deepseek-R1:14B.
- V100 performs well, achieving 48.63 tokens/s, making it a great choice for data centers.
- A5000 and A4000 are viable workstation choices, with 45.63 and 35.87 tokens/s, respectively.
- P100 has the slowest speed (18.99 tokens/s) and is not ideal for this model.

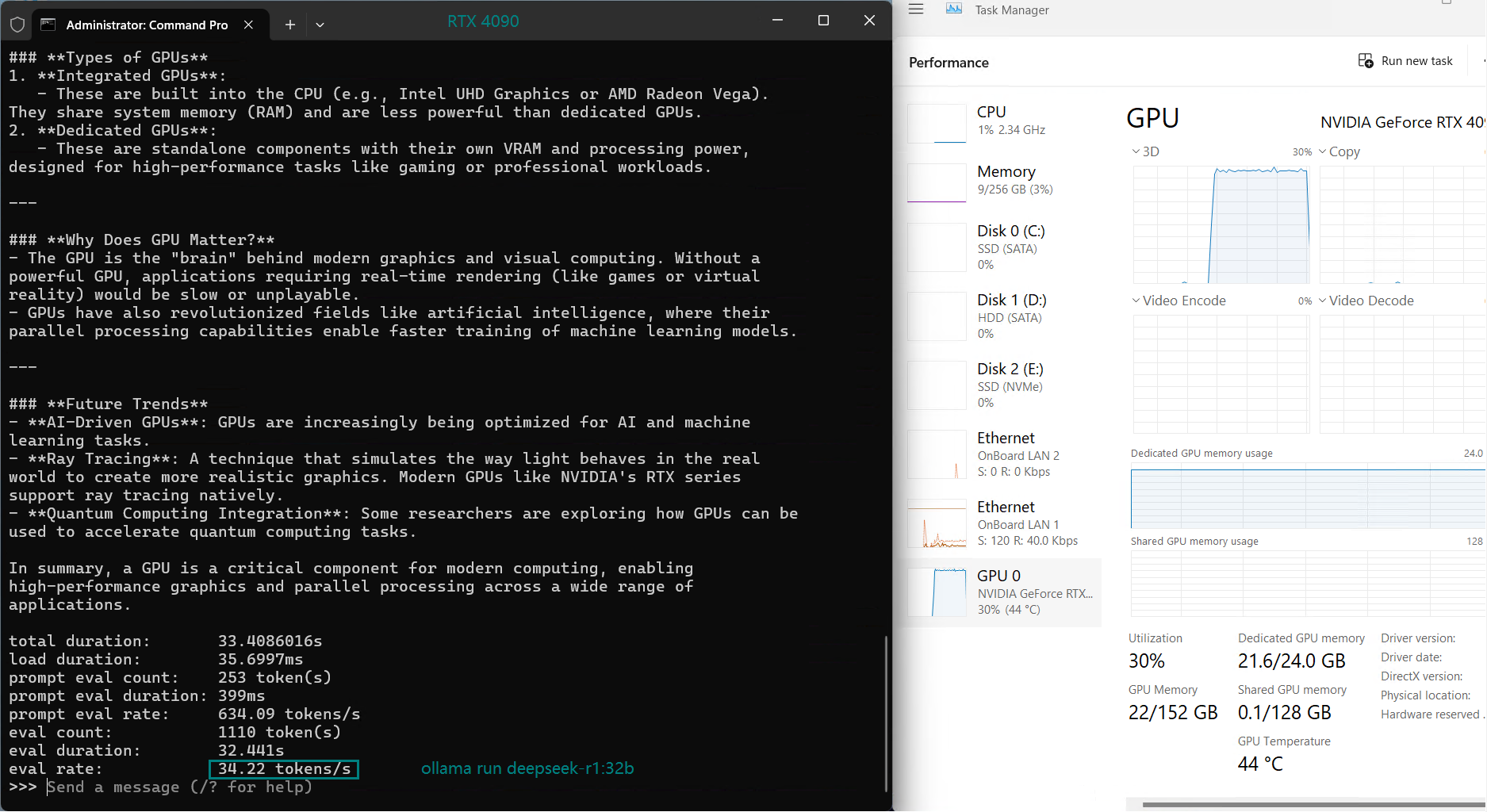
Best GPU for Deepseek-R1:14B on Ollama
✅ Best Overall Performance (High-end Choice)
- RTX4090 (Excellent performance, the best among consumer GPUs)
✅ Best Budget Option
- A4000 (Good performance at lower cost)
✅ Best for AI Workstations
- A5000 (Good balance between power and efficiency)
✅ Avoid
- P100 (Slowest performance, outdated)
Deepseek-R1:14B Server Recommendations
Recommended Server Specs
- GPU: RTX 4090 (best for single-node), V100 (best for clusters)
- CPU: At least 16 cores (AI reasoning does not require high CPU)
- RAM: Minimum 32GB RAM (64GB recommended for multi-instance setups)
- Storage: 1TB NVMe SSD (fast I/O speeds for model loading)
- Networking: 300M is OK for LLM Inference
Get Started with Cheap GPU Server for DeepSeek-r1 14B Hosting
Professional GPU VPS - A4000
- 32GB RAM
- 24 CPU Cores
- 320GB SSD
- 300Mbps Unmetered Bandwidth
- Once per 2 Weeks Backup
- OS: Linux / Windows 10/ Windows 11
- Dedicated GPU: Quadro RTX A4000
- CUDA Cores: 6,144
- Tensor Cores: 192
- GPU Memory: 16GB GDDR6
- FP32 Performance: 19.2 TFLOPS
- Available for Rendering, AI/Deep Learning, Data Science, CAD/CGI/DCC.
Advanced GPU Dedicated Server - V100
- 128GB RAM
- Dual 12-Core E5-2690v3
- 240GB SSD + 2TB SSD
- 100Mbps-1Gbps
- OS: Windows / Linux
- GPU: Nvidia V100
- Microarchitecture: Volta
- CUDA Cores: 5,120
- Tensor Cores: 640
- GPU Memory: 16GB HBM2
- FP32 Performance: 14 TFLOPS
- Cost-effective for AI, deep learning, data visualization, HPC, etc
Advanced GPU Dedicated Server - A5000
- 128GB RAM
- Dual 12-Core E5-2697v2
- 240GB SSD + 2TB SSD
- 100Mbps-1Gbps
- OS: Windows / Linux
- GPU: Nvidia Quadro RTX A5000
- Microarchitecture: Ampere
- CUDA Cores: 8192
- Tensor Cores: 256
- GPU Memory: 24GB GDDR6
- FP32 Performance: 27.8 TFLOPS
Enterprise GPU Dedicated Server - RTX 4090
- 256GB RAM
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- GPU: GeForce RTX 4090
- Microarchitecture: Ada Lovelace
- CUDA Cores: 16,384
- Tensor Cores: 512
- GPU Memory: 24 GB GDDR6X
- FP32 Performance: 82.6 TFLOPS
- Perfect for 3D rendering/modeling , CAD/ professional design, video editing, gaming, HPC, AI/deep learning.
Conclusion
Deepseek-R1:14B runs best on RTX 4090 and V100, offering the highest speed at 58.62 and 48.63 tokens/s, respectively. For budget-conscious setups, A4000 or A5000 provide good alternatives. Avoid outdated cards like P100 for inference workloads.
For setting up an inference server, prioritize high-performance GPUs, fast SSDs, and sufficient RAM to ensure smooth operation.
Would you like a guide on deploying Deepseek-R1:14B on a cloud server? Let me know in the comments!
deepseek-r1:14b test, deepseek-r1:14b benchmark, deepseek-r1:14b performance, deepseek-r1:14b ollama, deepseek-r1:14b server, best gpu for deepseek-r1:14b, deepseek-r1:14b gpu benchmark, deepseek-r1:14b rtx 4090, deepseek-r1:14b a5000, deepseek-r1:14b v100, deepseek-r1:14b p100, deepseek-r1:14b a4000, deepseek-r1:14b eval rate, deepseek-r1:14b inference, deepseek-r1:14b server recommendation, deepseek-r1:14b ollama test, deepseek-r1:14b cuda, deepseek-r1:14b gpu utilization, deepseek-r1:14b tensor cores