
























A100 40GB vLLM Benchmark: Cheap GPU for Gemma3, Llama and Qwen Hosting
Running large language models (LLMs) efficiently requires powerful GPUs. The NVIDIA A100 40GB emerges as an affordable yet powerful choice for hosting models under 16B parameters, making it ideal for cost-effective LLM inference. In this A100 vLLM benchmark, we evaluate its performance with vLLM, comparing inference speeds across models like Gemma 3-12B and Qwen 7B/14B, helping you determine the best cheap GPU for LLM inference.
Test Overview
1. A100 40GB GPU Details:
- GPU: Nvidia A100
- Microarchitecture: Ampere
- Compute capability: 8.0
- CUDA Cores: 6912
- Tensor Cores: 432
- Memory: 40GB HBM2
- FP32 performance: 19.5 TFLOPS
2. Test Project Code Source:
- We used this git project to build the environment(https://github.com/vllm-project/vllm)
3. The Following Models from Hugging Face were Tested:
- google/gemma-3-4b-it
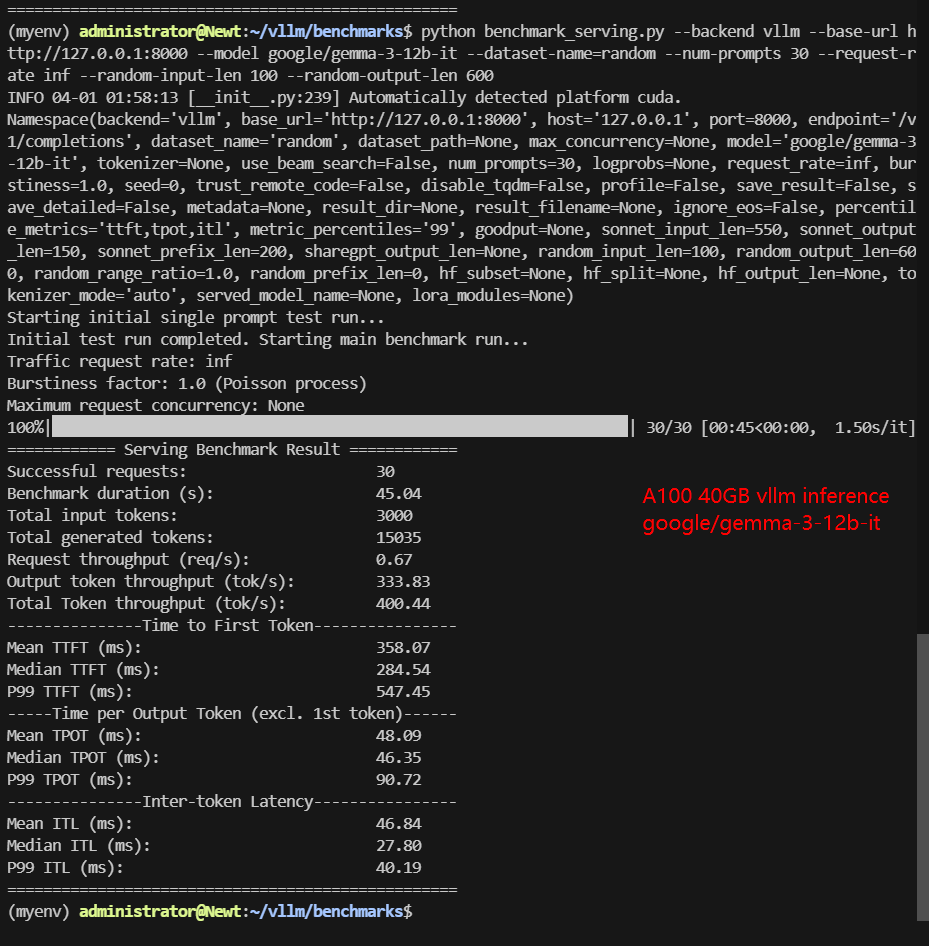
- google/gemma-3-12b-it
- Qwen/Qwen2.5-7B-Instruct
- Qwen/Qwen2.5-14B-Instruct
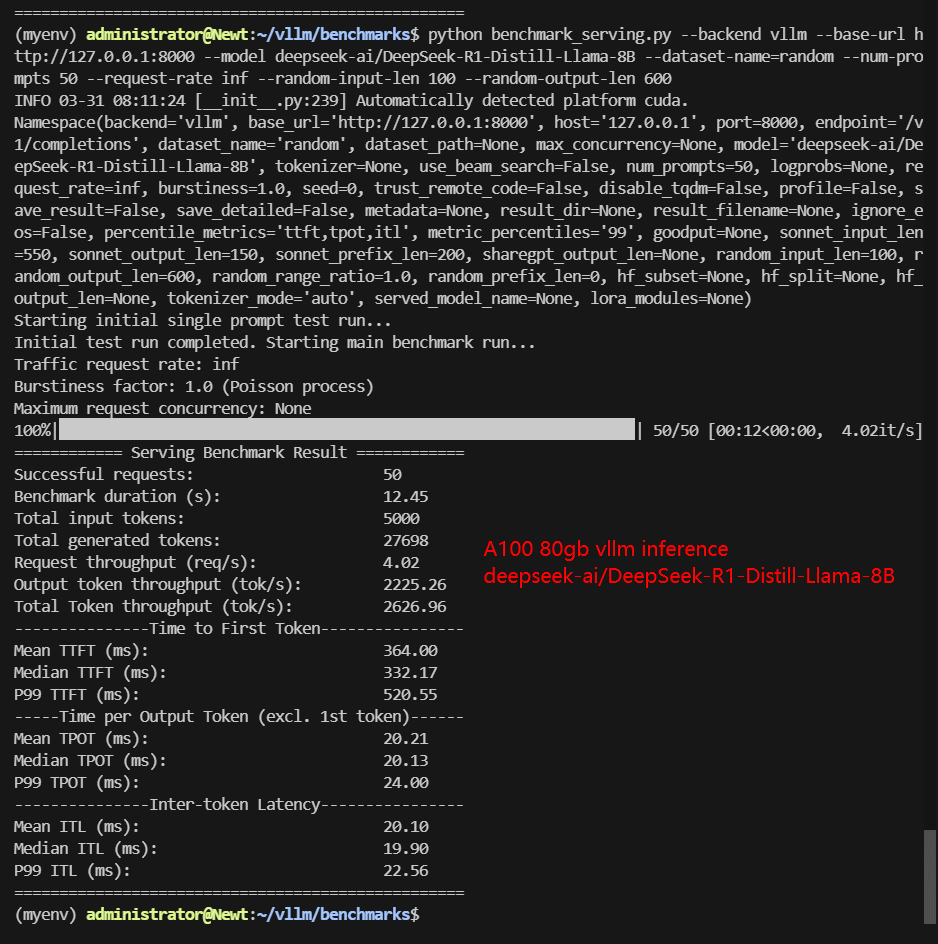
- deepseek-ai/DeepSeek-R1-Distill-Llama-8B
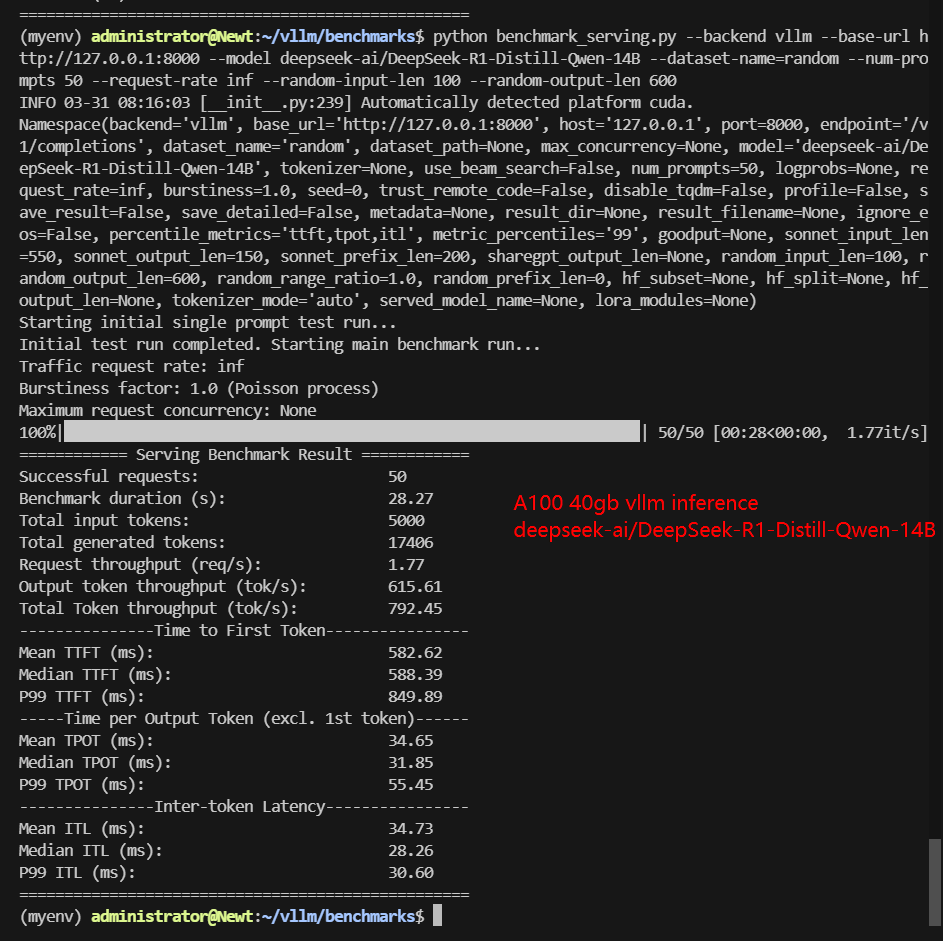
- deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
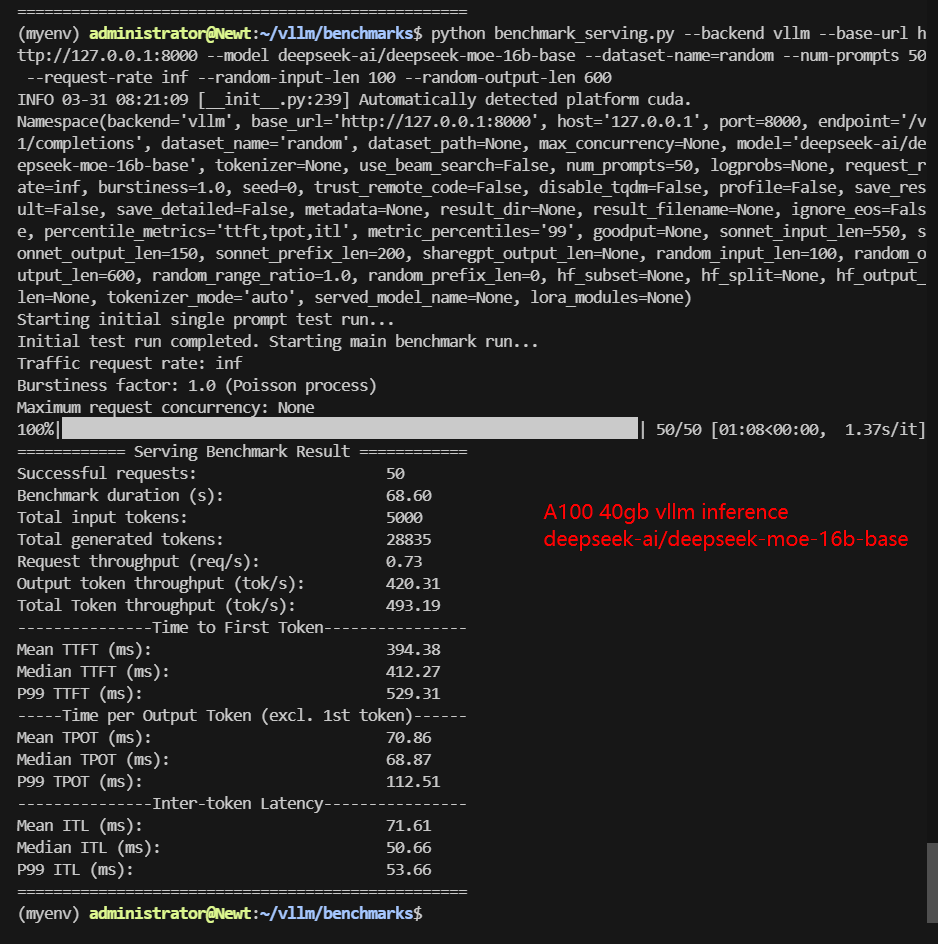
- deepseek-ai/deepseek-moe-16b-base
4. The Test Parameters are Preset as Follows:
- Input length: 100 tokens
- Output length: 600 tokens
- 50 concurrent requests
A100 40GB vLLM Benchmark for Gemma3, DeepSeek, and Qwen
| Models | gemma-3-4b-it | gemma-3-12b-it | Qwen2.5-7B-Instruct | Qwen2.5-14B-Instruct | DeepSeek-R1-Distill-Llama-8B | DeepSeek-R1-Distill-Qwen-14B | deepseek-moe-16b-base | gemma-3-12b-it |
|---|---|---|---|---|---|---|---|---|
| Quantization | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 |
| Size(GB) | 8.1 | 23 | 15 | 28 | 15 | 28 | 31 | 23 |
| Backend/Platform | vLLM | vLLM | vLLM | vLLM | vLLM | vLLM | vLLM | vLLM |
| Request Numbers | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 30 |
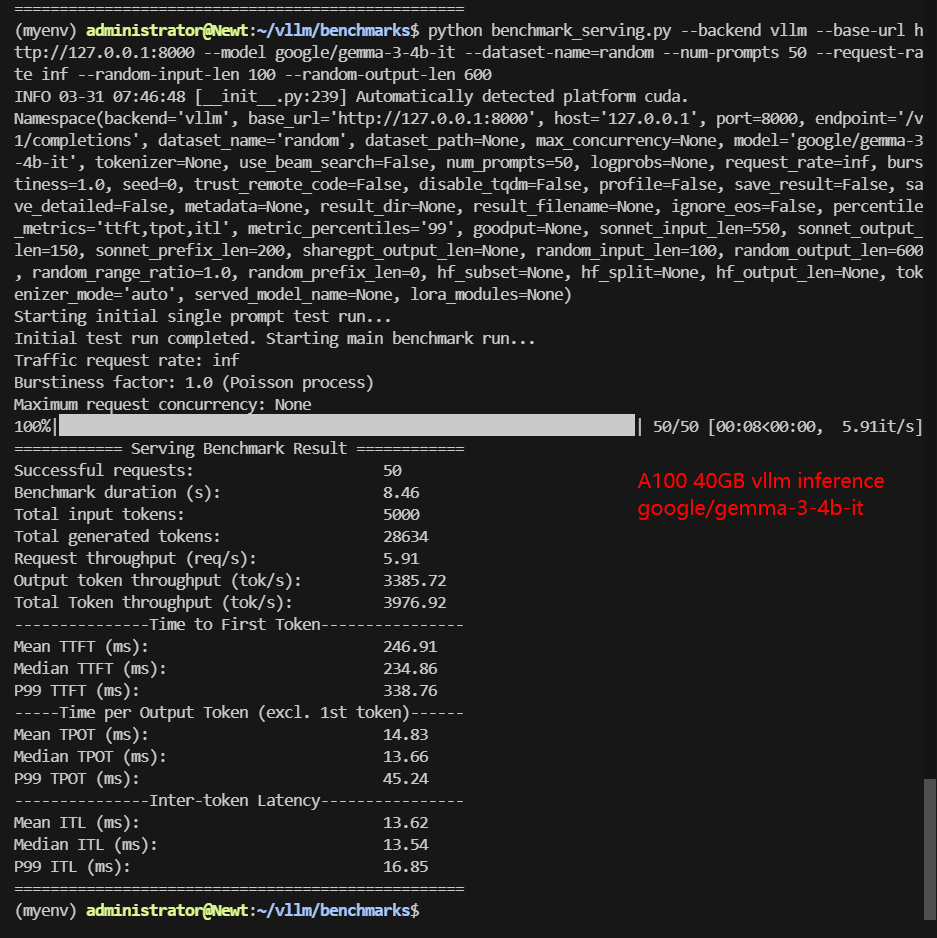
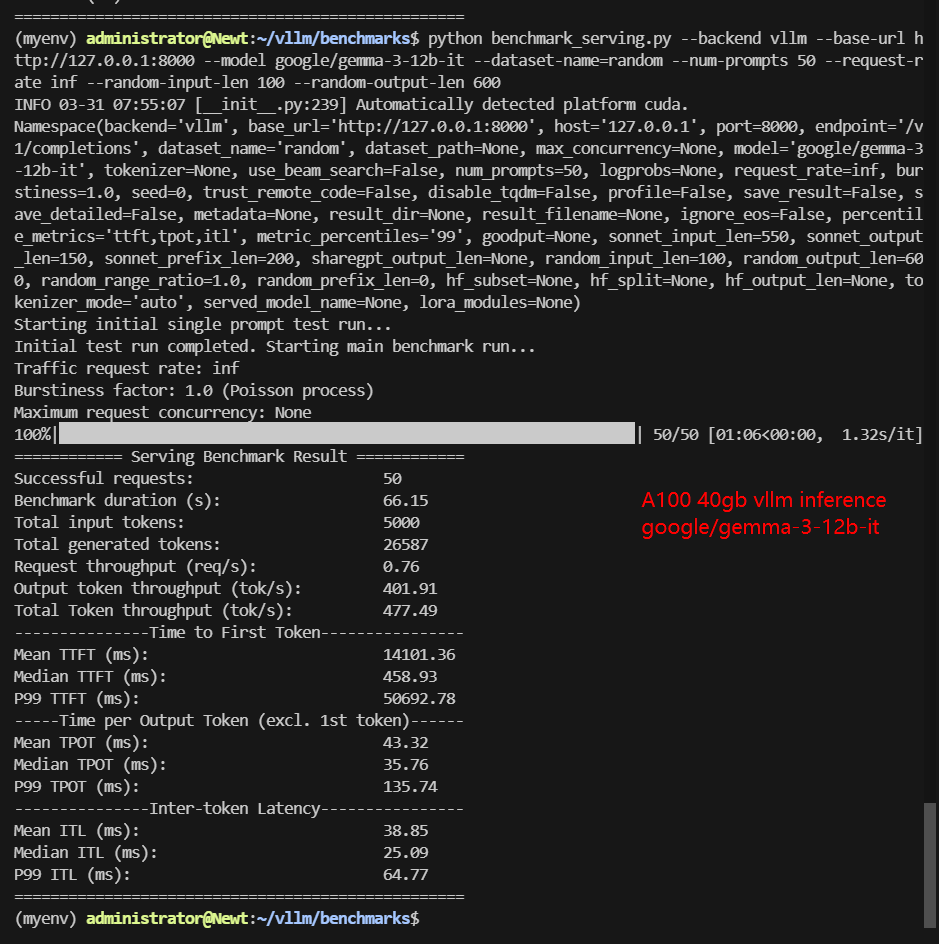
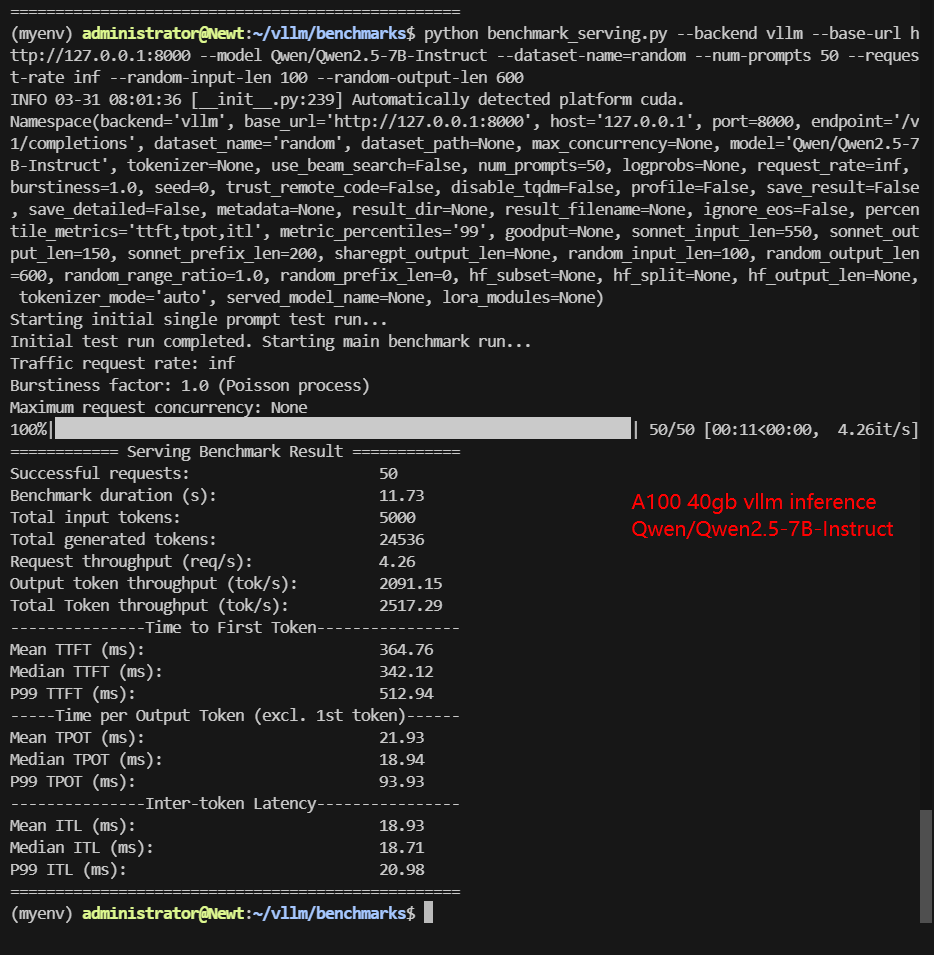
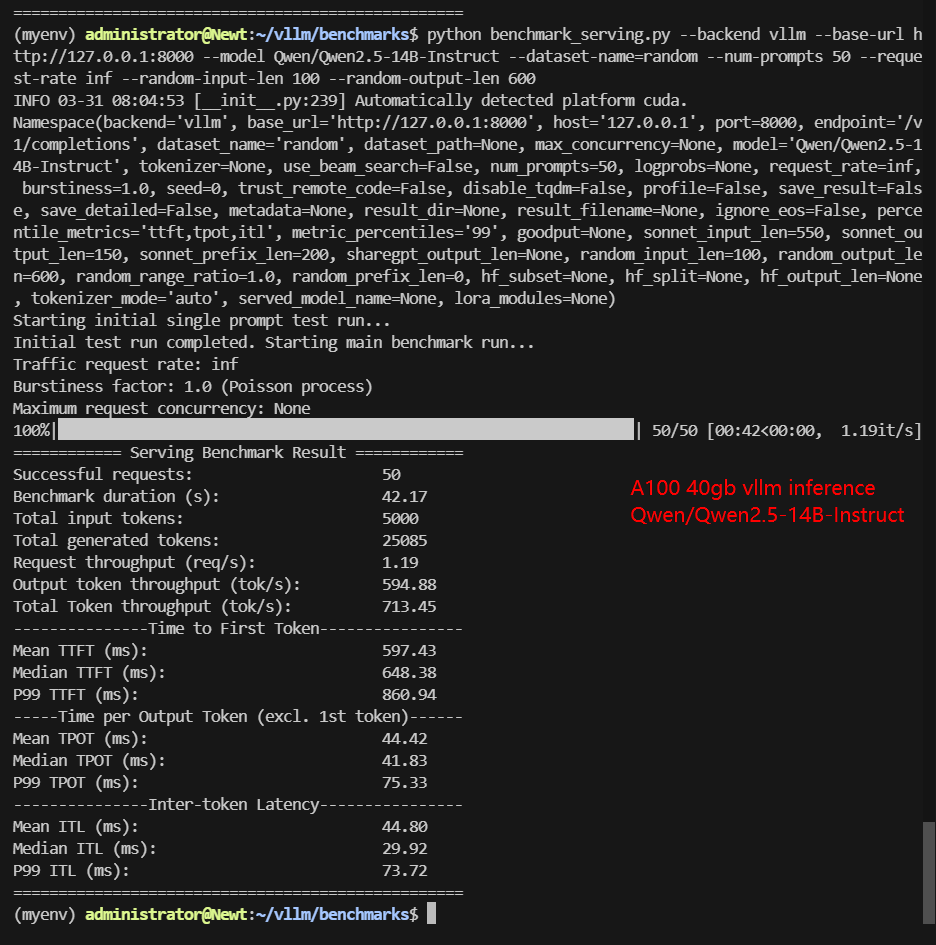
| Benchmark Duration(s) | 8.46 | 66.15 | 11.73 | 42.17 | 12.45 | 28.27 | 68.60 | 45.04 |
| Total Input Tokens | 5000 | 5000 | 5000 | 5000 | 5000 | 5000 | 5000 | 3000 |
| Total Generated Tokens | 28634 | 26587 | 24536 | 25085 | 27698 | 17406 | 28835 | 15035 |
| Request (req/s) | 5.91 | 0.76 | 4.26 | 1.19 | 4.02 | 1.77 | 0.73 | 0.67 |
| Input (tokens/s) | 591.2 | 75.58 | 426.14 | 138.57 | 401.7 | 176.84 | 72.88 | 66.61 |
| Output (tokens/s) | 3385.72 | 401.91 | 2091.15 | 574.88 | 2225.26 | 615.61 | 420.31 | 333.83 |
| Total Throughput (tokens/s) | 3976.92 | 477.49 | 2517.29 | 713.45 | 2626.96 | 792.45 | 493.19 | 400.44 |
| Median TTFT (ms) | 234.86 | 458.93 | 342.12 | 648.38 | 332.17 | 588.39 | 412.27 | 284.54 |
| P99 TTFT (ms) | 338.76 | 50692.78 | 512.94 | 860.94 | 520.55 | 849.89 | 529.31 | 547.45 |
| Median TPOT (ms) | 13.66 | 35.76 | 18.94 | 41.83 | 20.13 | 31.85 | 68.87 | 46.35 |
| P99 TPOT (ms) | 45.24 | 135.74 | 93.93 | 75.33 | 24.00 | 55.45 | 112.51 | 90.72 |
| Median Eval Rate (tokens/s) | 73.20 | 27.96 | 52.80 | 23.91 | 49.68 | 31.40 | 14.52 | 21.57 |
| P99 Eval Rate (tokens/s) | 22.10 | 7.37 | 10.65 | 13.27 | 14.67 | 18.03 | 8.89 | 11.02 |
✅ Key Takeaways:
- Best Performance for Small Models: Gemma3-4B (3,976 tokens/s) outperforms all others, making it ideal for high-speed LLM serving.
- A100 Handles Up to 8B Efficiently: Qwen-7B and DeepSeek-R1-8B achieve 2,500+ tokens/s with sub-350ms latency, confirming A100’s viability for models in this range, and it can also support a higher number of concurrent.
- P99 TFFT of Gemma3-12B spikes to 50.7s—indicating occasional stalls in larger models. It is recommended to reduce the concurrency to 30 for the shortest latency.
- Scaling Beyond 12B Reduces Throughput: Performance drops significantly for 14B-16B models, but still acceptable.
Why Choose A100 40GB for vLLM Inference?
For those running Gemma3-12B, DeepSeek-R1, or Qwen models, A100 provides a cost-effective hosting option without sacrificing performance.
A100 40GB Server: Cheap GPU for Gemma3-12B Hosting
If you're looking for an affordable yet powerful GPU to run Gemma3-12B, the A100 40GB and 2*RTX4090 is the best budget option. With 40GB VRAM usage, it efficiently handles Gemma3 4B and 12B inference while keeping costs low.
To optimize inference performance and minimize latency for Gemma3-12B, we recommend limiting concurrent requests to 30. This prevents excessive queuing and ensures faster token generation times, improving real-time responsiveness in LLM deployments.
Get Started with A100 40GB Server Hosting
A100 40GB provides stable inference performance, making it a cheap choice for Gemma3-12B Hosting and Qwen-14B Hosting.
Enterprise GPU Dedicated Server - A100
- 256GB RAM
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- GPU: Nvidia A100
- Microarchitecture: Ampere
- CUDA Cores: 6912
- Tensor Cores: 432
- GPU Memory: 40GB HBM2
- FP32 Performance: 19.5 TFLOPS
- Good alternativeto A800, H100, H800, L40. Support FP64 precision computation, large-scale inference/AI training/ML.etc
Enterprise GPU Dedicated Server - RTX A6000
- 256GB RAM
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- GPU: Nvidia Quadro RTX A6000
- Microarchitecture: Ampere
- CUDA Cores: 10,752
- Tensor Cores: 336
- GPU Memory: 48GB GDDR6
- FP32 Performance: 38.71 TFLOPS
- Optimally running AI, deep learning, data visualization, HPC, etc.
Multi-GPU Dedicated Server- 2xRTX 4090
- 256GB RAM
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 1Gbps
- OS: Windows / Linux
- GPU: 2 x GeForce RTX 4090
- Microarchitecture: Ada Lovelace
- CUDA Cores: 16,384
- Tensor Cores: 512
- GPU Memory: 24 GB GDDR6X
- FP32 Performance: 82.6 TFLOPS
Enterprise GPU Dedicated Server - A100(80GB)
- 256GB RAM
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- GPU: Nvidia A100
- Microarchitecture: Ampere
- CUDA Cores: 6912
- Tensor Cores: 432
- GPU Memory: 80GB HBM2e
- FP32 Performance: 19.5 TFLOPS
Conclusion: A100 is a Cheap Choice for LLMs Under 16B
- For models under 8B, A100 delivers high throughput and low latency. The concurrency can reach 100 Requests.
- For 12B-16B models, performance drops, but vLLM optimizations help maintain usability. The concurrency can reach 50 Requests.
- For Gemma3-12b, it is recommended to limit concurrent requests to 30-35 for lowest latency.
Attachment: Video Recording of A100 40GB vLLM Benchmark
Data Item Explanation in the Table:
- Quantization: The number of quantization bits. This test uses 16 bits, a full-blooded model.
- Size(GB): Model size in GB.
- Backend: The inference backend used. In this test, vLLM is used.
- Successful Requests: The number of requests processed.
- Benchmark duration(s): The total time to complete all requests.
- Total input tokens: The total number of input tokens across all requests.
- Total generated tokens: The total number of output tokens generated across all requests.
- Request (req/s): The number of requests processed per second.
- Input (tokens/s): The number of input tokens processed per second.
- Output (tokens/s): The number of output tokens generated per second.
- Total Throughput (tokens/s): The total number of tokens processed per second (input + output).
- Median TTFT(ms): The time from when the request is made to when the first token is received, in milliseconds. A lower TTFT means that the user is able to get a response faster.
- P99 TTFT (ms): The 99th percentile Time to First Token, representing the worst-case latency for 99% of requests—lower is better to ensure consistent performance.
- Median TPOT(ms): The time required to generate each output token, in milliseconds. A lower TPOT indicates that the system is able to generate a complete response faster.
- P99 TPOT (ms): The 99th percentile Time Per Output Token, showing the worst-case delay in token generation—lower is better to minimize response variability.
- Median Eval Rate(tokens/s): The number of tokens evaluated per second per user. A high evaluation rate indicates that the system is able to serve each user efficiently.
- P99 Eval Rate(tokens/s): The number of tokens evaluated per second by the 99th percentile user represents the worst user experience.
A100 vLLM, A100 inference, cheap GPU LLM inference, Gemma 3 hosting, Gemma 3-4B hosting,Gemma 3-12B hosting, vLLM benchmark, A100 40GB vs H100, best GPU for LLM, affordable LLM inference, multi-GPU inference, vLLM distributed architecture