
























A40 vLLM Benchmark: 7B to 14B LLMs Under 50 & 100 Concurrent Requests
As large language models (LLMs) become integral to modern AI deployments, efficient hosting with optimized inference latency is key. This report benchmarks the performance of the NVIDIA A40 (48GB) using the vLLM inference engine under 50 and 100 concurrent request conditions, testing various 7B to 14B models, including DeepSeek, Qwen, Meta-LLaMA, and Gemma3.
Test Overview
1. A40 GPU Details:
- GPU: Nvidia A40
- Microarchitecture: Ampere
- Compute capability: 8.6
- CUDA Cores: 10,752
- Tensor Cores: 336
- Memory: 48GB GDDR6
- FP32 performance: 37.48 TFLOPS
2. Test Project Code Source:
- We used this git project to build the environment(https://github.com/vllm-project/vllm)
3. The Following Models from Hugging Face were Tested:
- meta-llama/Llama-3.1-8B-Instruct
- deepseek-ai/DeepSeek-R1-Distill-Llama-8B
- deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
- Qwen/Qwen2.5-14B-Instruct
- Qwen/Qwen2.5-7B-Instruct
- google/gemma-3-12b-it
4. The Test Parameters are Preset as Follows:
- Input length: 100 tokens
- Output length: 600 tokens
5. We conducted two rounds of A40 vLLM tests under different concurrent request loads:
- Scenario 1: 50 concurrent requests
- Scenario 2: 100 concurrent requests
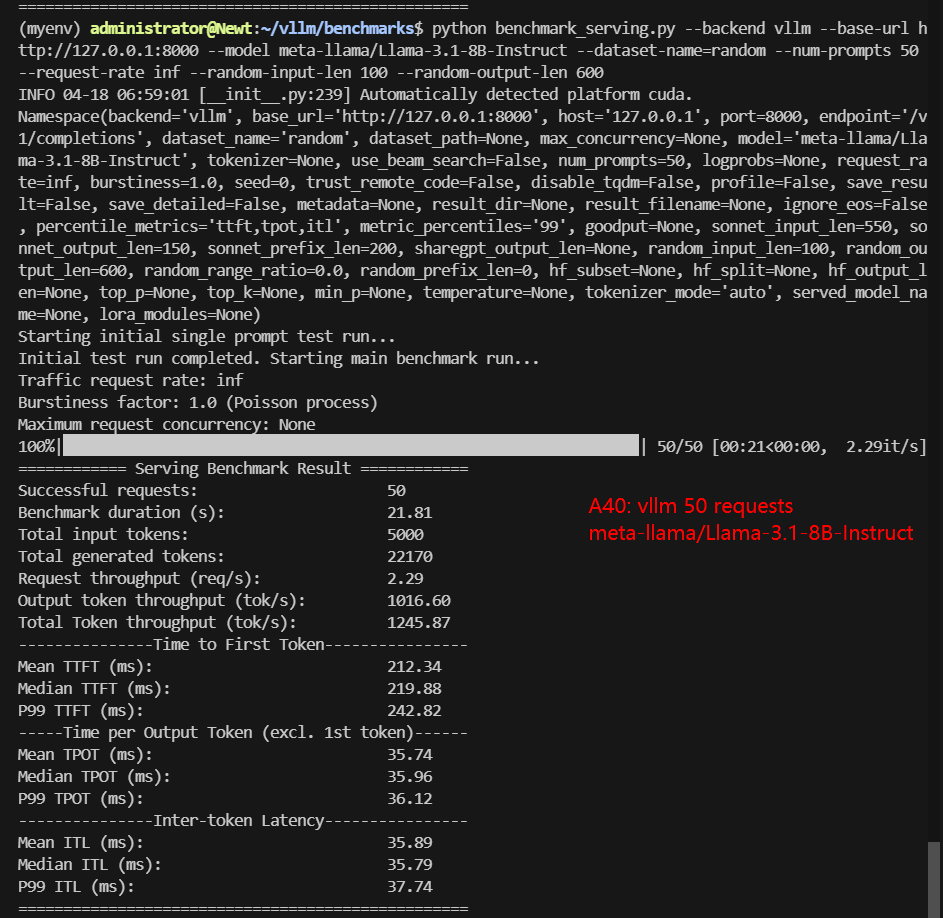
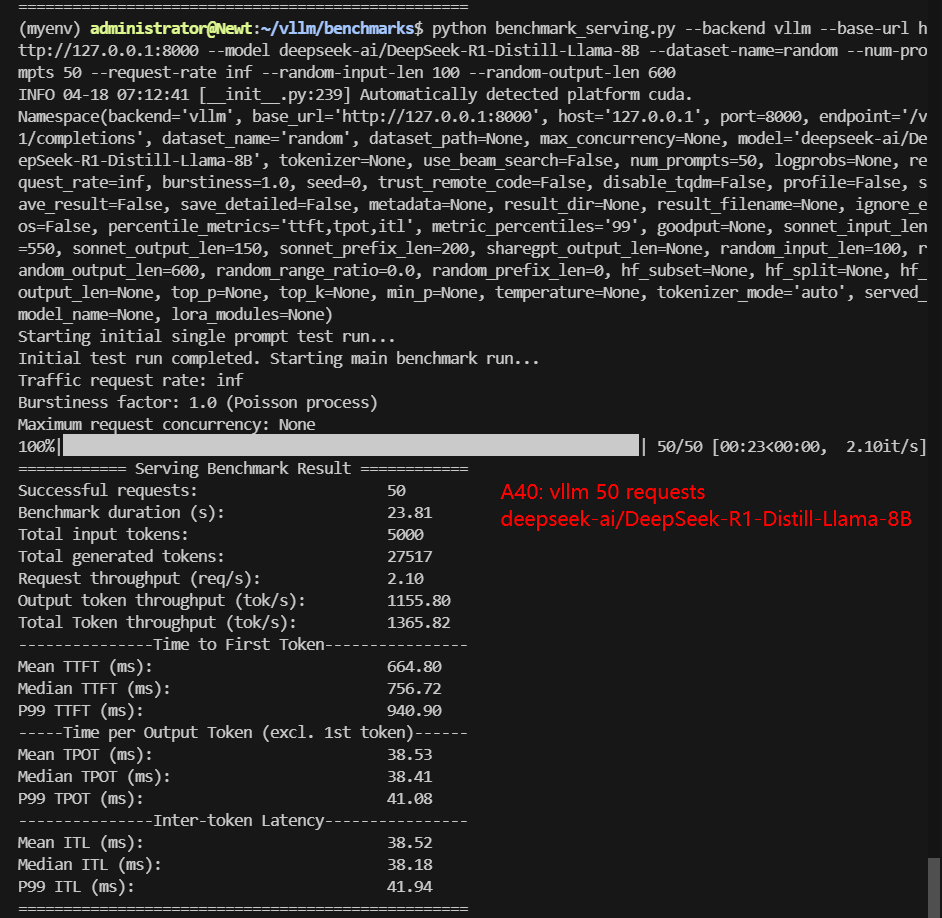
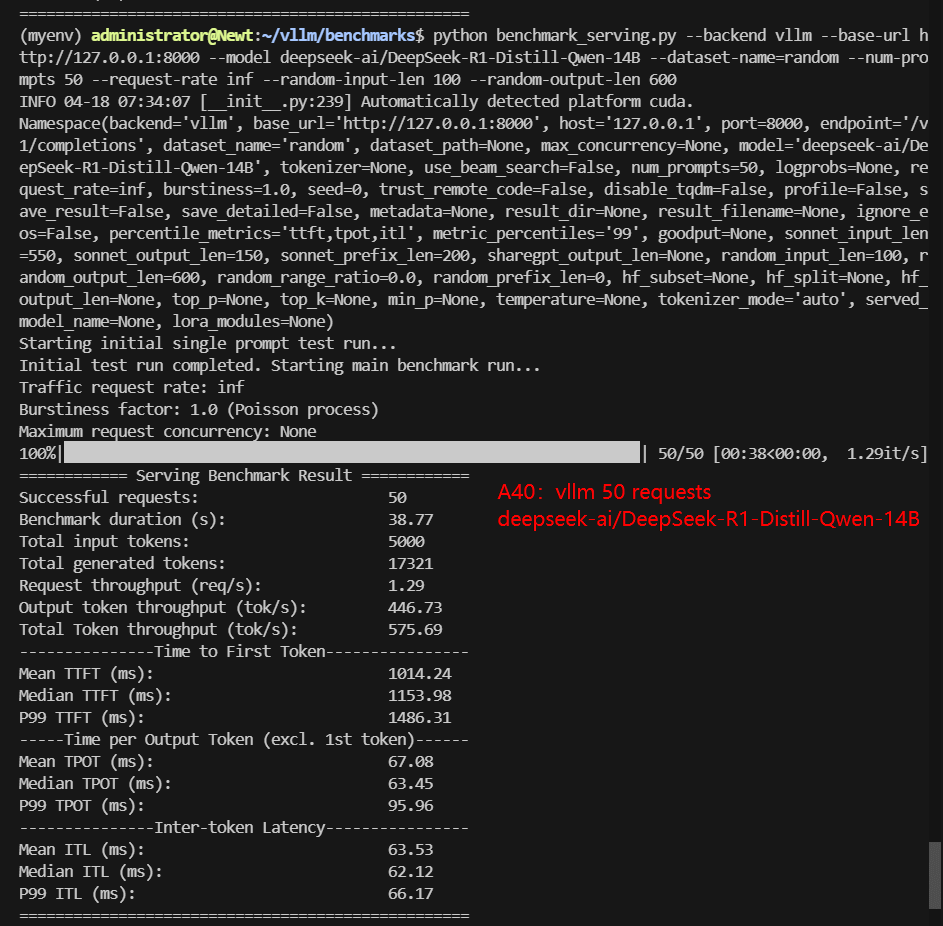
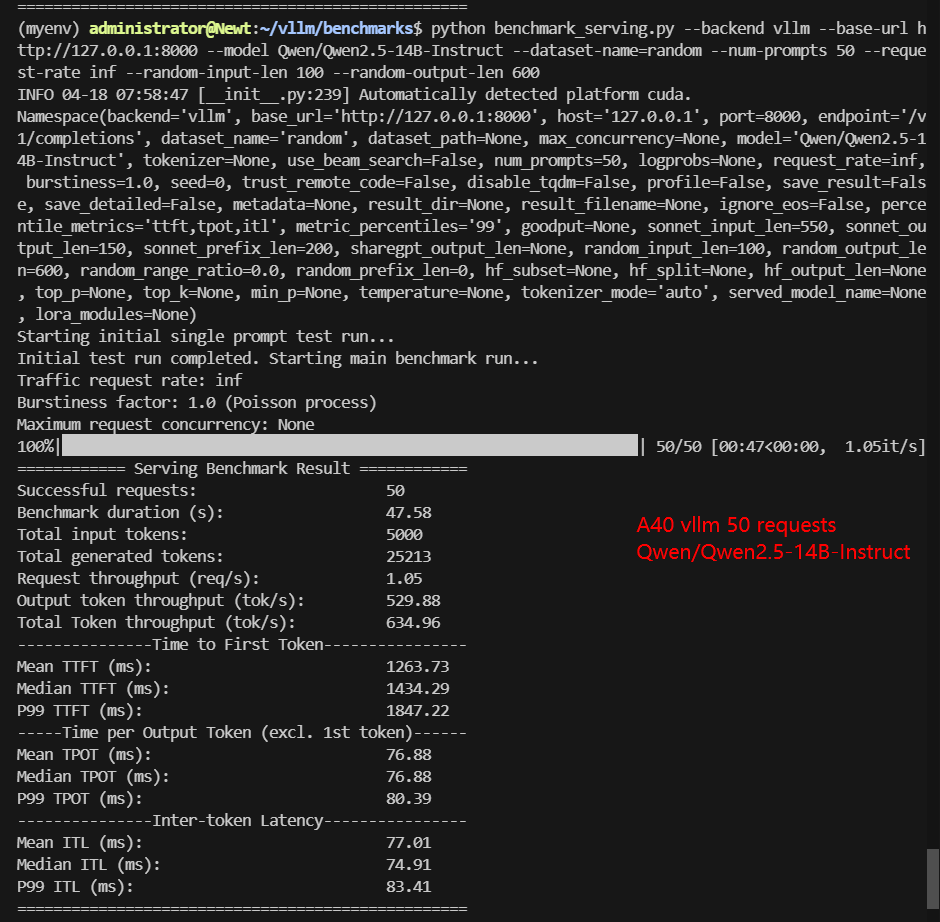
A40 Benchmark for Scenario 1: 50 Concurrent Requests
| Models | meta-llama/Llama-3.1-8B-Instruct | deepseek-ai/DeepSeek-R1-Distill-Llama-8B | deepseek-ai/DeepSeek-R1-Distill-Qwen-14B | Qwen/Qwen2.5-14B-Instruct | Qwen/Qwen2.5-7B-Instruct | google/gemma-3-12b-it |
|---|---|---|---|---|---|---|
| Quantization | 16 | 16 | 16 | 16 | 16 | 16 |
| Size(GB) | 15 | 15 | 28 | 28 | 15 | 23 |
| Backend/Platform | vLLM | vLLM | vLLM | vLLM | vLLM | vLLM |
| Request Numbers | 50 | 50 | 50 | 50 | 50 | 50 |
| Benchmark Duration(s) | 21.81 | 23.81 | 38.77 | 47.58 | 23.48 | 65.02 |
| Total Input Tokens | 5000 | 5000 | 5000 | 5000 | 5000 | 5000 |
| Total Generated Tokens | 22170 | 27517 | 17321 | 25213 | 25703 | 27148 |
| Request (req/s) | 2.29 | 2.10 | 1.29 | 1.05 | 2.13 | 0.77 |
| Input (tokens/s) | 229.27 | 210.02 | 128.96 | 105.08 | 212.93 | 76.9 |
| Output (tokens/s) | 1016.60 | 1155.80 | 446.73 | 529.88 | 1094.54 | 417.54 |
| Total Throughput (tokens/s) | 1245.87 | 1365.82 | 575.69 | 634.96 | 1307.47 | 494.44 |
| Median TTFT(ms) | 219.88 | 756.72 | 1153.98 | 1434.29 | 761.11 | 401.22 |
| P99 TTFT(ms) | 242.82 | 940.90 | 1486.31 | 1847.22 | 983.28 | 573.97 |
| Median TPOT(ms) | 35.96 | 38.41 | 63.45 | 76.88 | 37.82 | 107.74 |
| P99 TPOT(ms) | 36.12 | 41.08 | 95.96 | 80.39 | 190.41 | 115.72 |
| Median Eval Rate(tokens/s) | 27.81 | 26.03 | 15.76 | 13.01 | 26.44 | 9.28 |
| P99 Eval Rate(tokens/s) | 27.69 | 24.34 | 10.42 | 12.44 | 5.25 | 8.64 |
✅ Key Takeaways:
- 8B models (Llama-3, DeepSeek, Qwen-7B) perform optimally.
- 14B models are usable but slower.
- The Gemma-3-12B and DeepSeek 14B models begin to push the limits of the GPU memory, especially when using longer sequence lengths.
- At 50 requests, the A40 shows strong baseline performance across models, especially in token generation and throughput. However, it’s clear from later results that the GPU is not fully saturated at this level for most models.
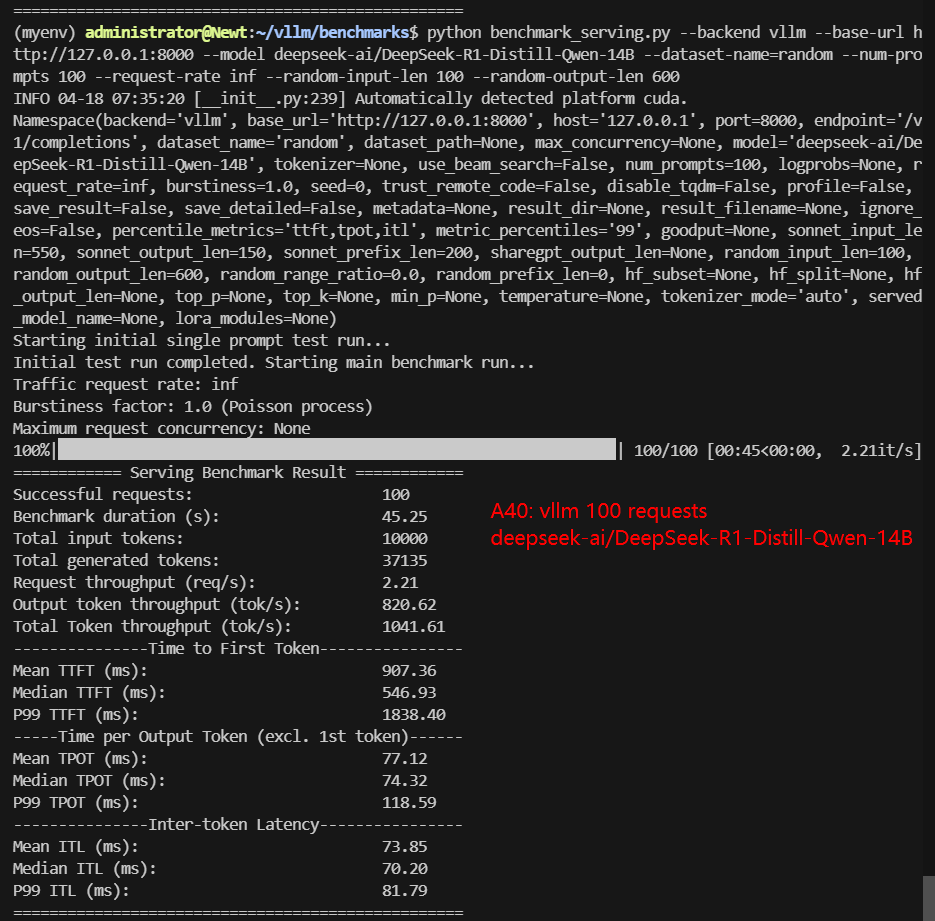
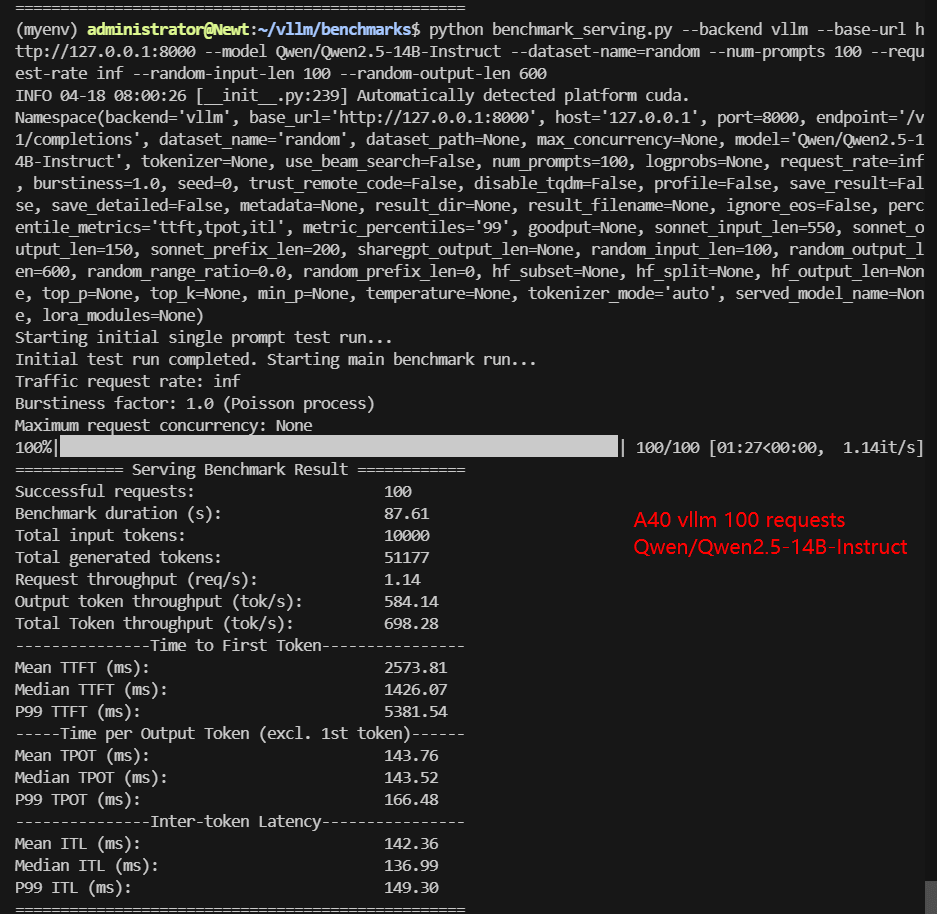
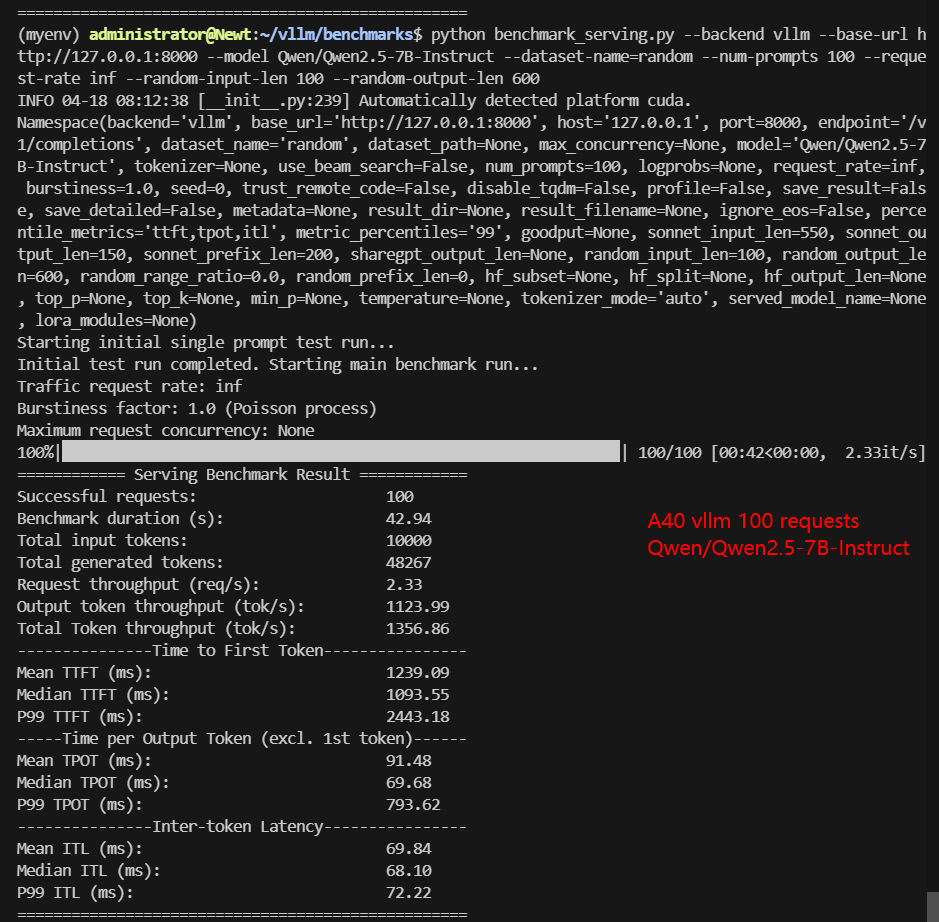
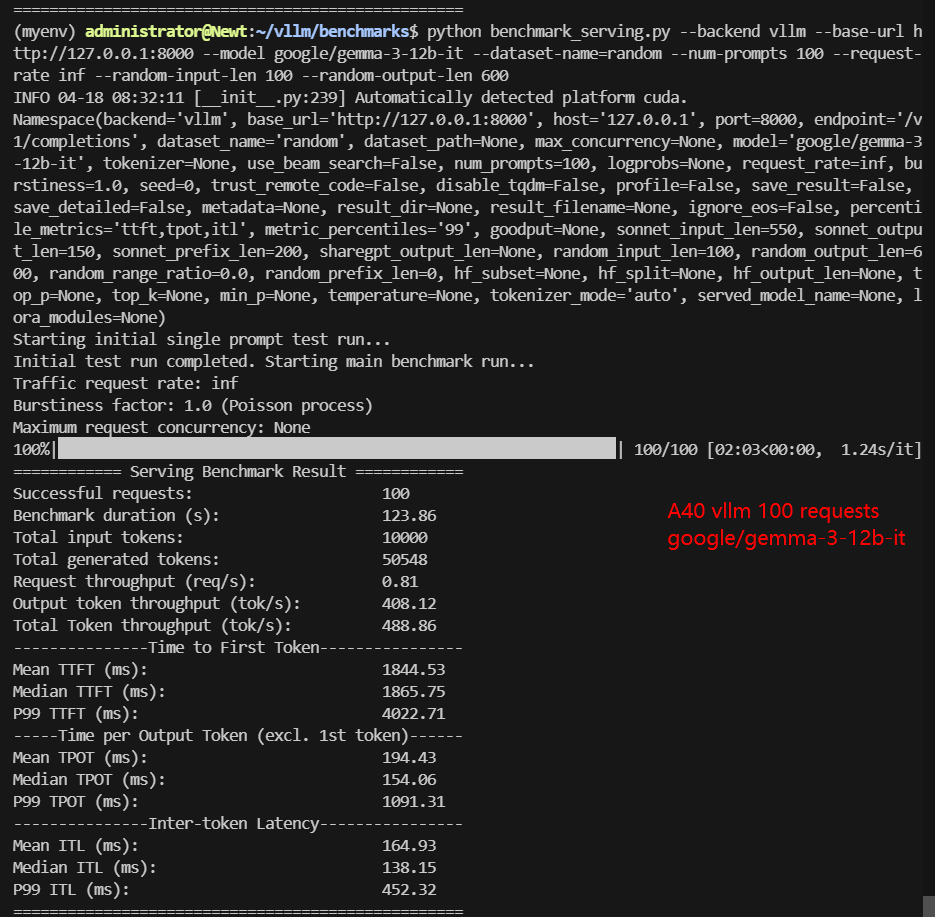
A6000 Benchmark for Scenario 2: 100 Concurrent Requests
| Models | meta-llama/Llama-3.1-8B-Instruct | deepseek-ai/DeepSeek-R1-Distill-Llama-8B | deepseek-ai/DeepSeek-R1-Distill-Qwen-14B | Qwen/Qwen2.5-14B-Instruct | Qwen/Qwen2.5-7B-Instruct | google/gemma-3-12b-it |
|---|---|---|---|---|---|---|
| Quantization | 16 | 16 | 16 | 16 | 16 | 16 |
| Size(GB) | 15 | 15 | 28 | 28 | 15 | 23 |
| Backend/Platform | vLLM | vLLM | vLLM | vLLM | vLLM | vLLM |
| Request Numbers | 100 | 100 | 100 | 100 | 100 | 100 |
| Benchmark Duration(s) | 26.61 | 40.83 | 45.25 | 87.61 | 42.94 | 123.86 |
| Total Input Tokens | 10000 | 10000 | 10000 | 10000 | 10000 | 10000 |
| Total Generated Tokens | 45375 | 54430 | 37135 | 51177 | 48267 | 50548 |
| Request (req/s) | 3.76 | 2.45 | 2.21 | 1.14 | 2.33 | 0.81 |
| Input (tokens/s) | 375.86 | 244.94 | 220.99 | 114.14 | 241.87 | 80.74 |
| Output (tokens/s) | 1705.49 | 1333.21 | 820.62 | 584.14 | 1123.99 | 408.12 |
| Total Throughput (tokens/s) | 2081.35 | 1578.15 | 1041.61 | 698.28 | 1356.86 | 488.86 |
| Median TTFT(ms) | 487.81 | 671.18 | 546.93 | 1426.07 | 1093.55 | 1865.75 |
| P99 TTFT(ms) | 1065.56 | 1422.67 | 1838.40 | 5381.54 | 2443.18 | 4022.71 |
| Median TPOT(ms) | 43.43 | 66.86 | 74.32 | 143.52 | 69.68 | 154.06 |
| P99 TPOT(ms) | 64.93 | 67.43 | 118.59 | 166.48 | 793.62 | 1091.31 |
| Median Eval Rate(tokens/s) | 23.03 | 14.86 | 13.45 | 6.97 | 14.35 | 6.49 |
| P99 Eval Rate(tokens/s) | 43.42 | 14.83 | 8.43 | 6.01 | 1.26 | 0.92 |
✅ Key Takeaways:
- A40 can handle 8B models efficiently even at high concurrency.
- 14B models (Qwen/DeepSeek) are usable but with higher latency.
- Gemma-3-12B is not recommended for A40 due to poor scaling.
- The A40 successfully handled 100 concurrent requests with all tested 14B models, proving that it is viable for real-world LLM inference at scale, especially for models like DeepSeek and Qwen.
- Doubling to 100 requests shows a clear rise in token throughput — indicating that the A40 still had headroom at 50 requests, particularly for 14B models.
Insights for A40 vLLM Performance
✅ Best for 7B-8B Models:
✅ 14B Models Possible but Slower:
✅ Avoid Gemma3-12b 100 requests on A40
⚠️Operational Notes
- Enable --max-model-len 4096 when running 14B models. Without it, vLLM will fail to load them.
- Temperature Warning: A40 can reach 80°C+ under load. It is recommended to manually trigger fan cooling for 5 minutes during high workloads.
- The data of Gemma3-12b is not ideal and can only support 50 concurrent requests. If more concurrent requests are required, it is recommended to use a100 40gb to infer Gemma3-12b.
Get Started with Nvidia A40 Server Rental!
Interested in optimizing your vLLM deployment? Check out our cheap GPU server hosting services or explore alternative GPUs for high-end AI inference.
Enterprise GPU Dedicated Server - RTX 4090
- 256GB RAM
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- GPU: GeForce RTX 4090
- Microarchitecture: Ada Lovelace
- CUDA Cores: 16,384
- Tensor Cores: 512
- GPU Memory: 24 GB GDDR6X
- FP32 Performance: 82.6 TFLOPS
- Perfect for 3D rendering/modeling , CAD/ professional design, video editing, gaming, HPC, AI/deep learning.
Enterprise GPU Dedicated Server - A40
- 256GB RAM
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- GPU: Nvidia A40
- Microarchitecture: Ampere
- CUDA Cores: 10,752
- Tensor Cores: 336
- GPU Memory: 48GB GDDR6
- FP32 Performance: 37.48 TFLOPS
- Ideal for hosting AI image generator, deep learning, HPC, 3D Rendering, VR/AR etc.
Enterprise GPU Dedicated Server - A100
- 256GB RAM
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- GPU: Nvidia A100
- Microarchitecture: Ampere
- CUDA Cores: 6912
- Tensor Cores: 432
- GPU Memory: 40GB HBM2
- FP32 Performance: 19.5 TFLOPS
- Good alternativeto A800, H100, H800, L40. Support FP64 precision computation, large-scale inference/AI training/ML.etc
Enterprise GPU Dedicated Server - A100(80GB)
- 256GB RAM
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- GPU: Nvidia A100
- Microarchitecture: Ampere
- CUDA Cores: 6912
- Tensor Cores: 432
- GPU Memory: 80GB HBM2e
- FP32 Performance: 19.5 TFLOPS
Conclusion: A40 is the Cheapest Choice for 14B LLMs
The NVIDIA A40 is excellent for 7B-8B models (DeepSeek, Llama-3, Qwen-7B) even at 100+ concurrent requests. While 14B models work, they require optimizations (--max-model-len 4096) and thermal monitoring.
The A40 is a robust and cost-effective GPU for LLM inference up to 14B, comfortably supporting up to 100 concurrent requests. With minor tuning, it is well-suited for multi-user inference workloads and production-scale deployments of open-weight LLMs. For scalable hosting of LLaMA, Qwen, DeepSeek and other 7–14B models, the A40 stands out as a reliable mid-tier GPU choice.
Attachment: Video Recording of A40 vLLM Benchmark
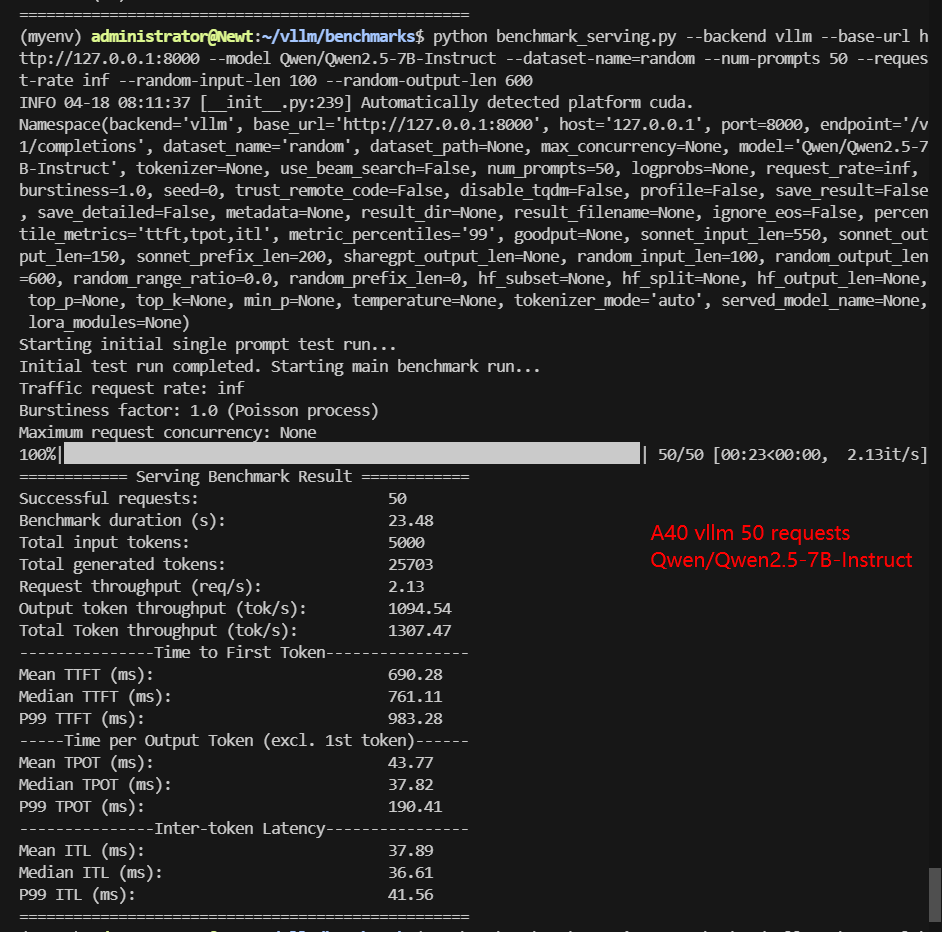
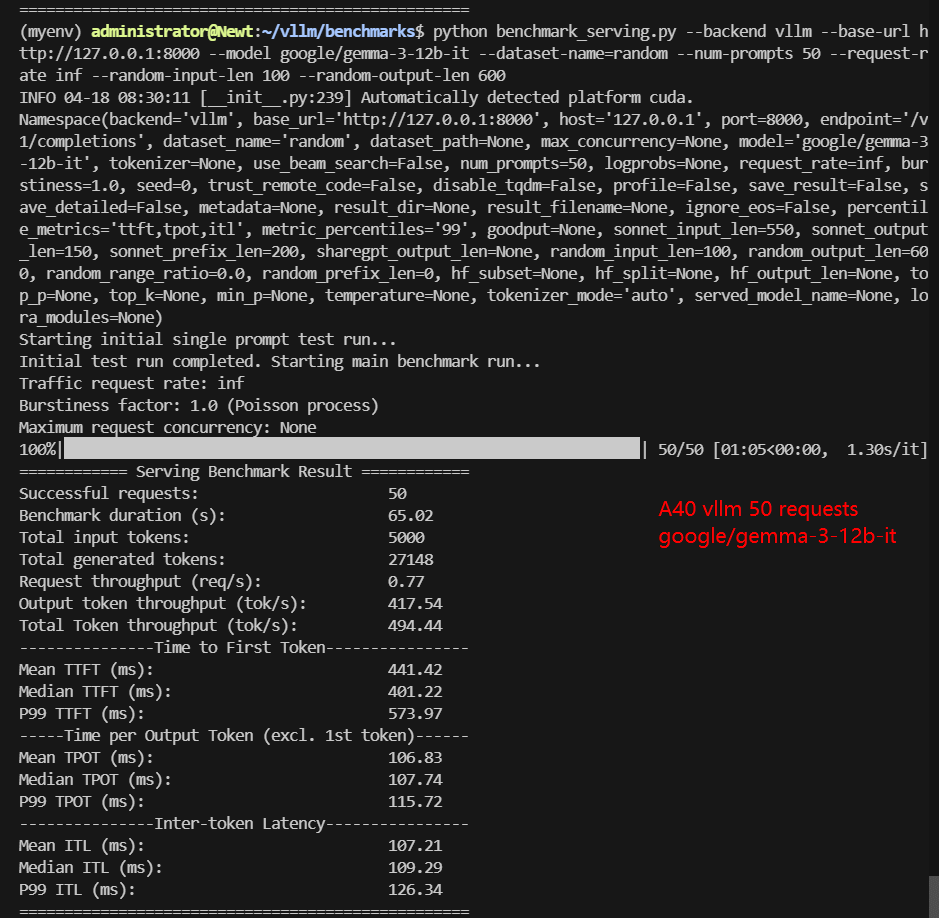
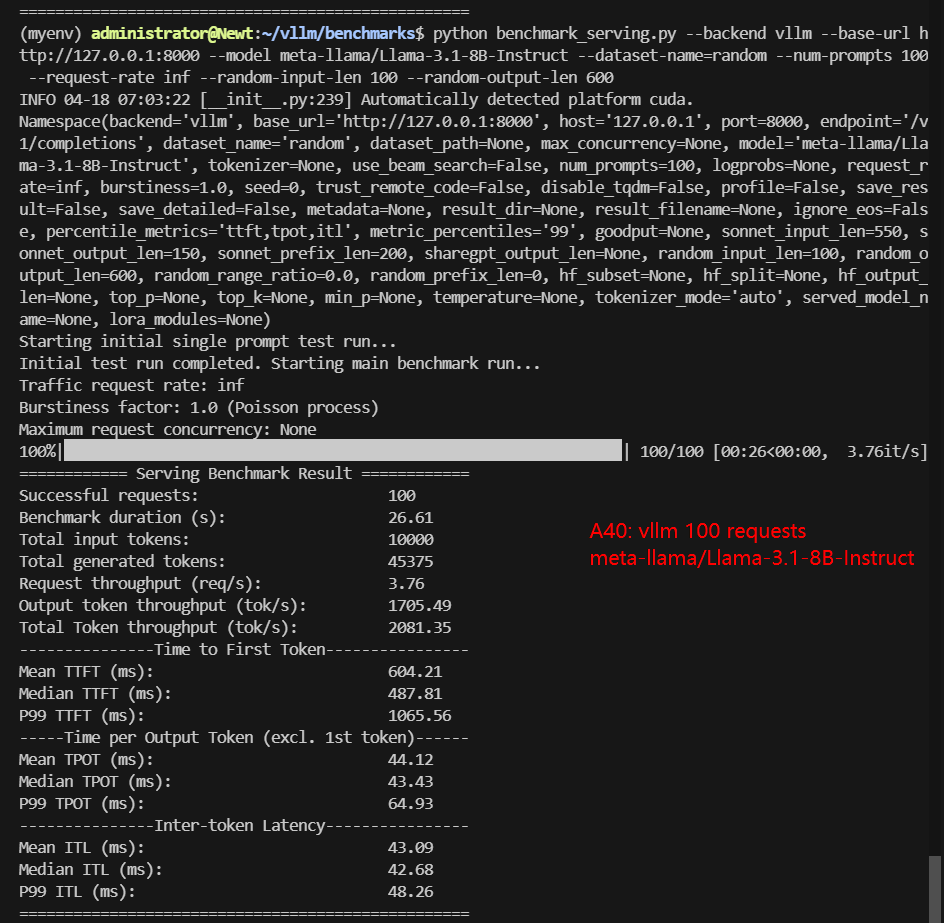
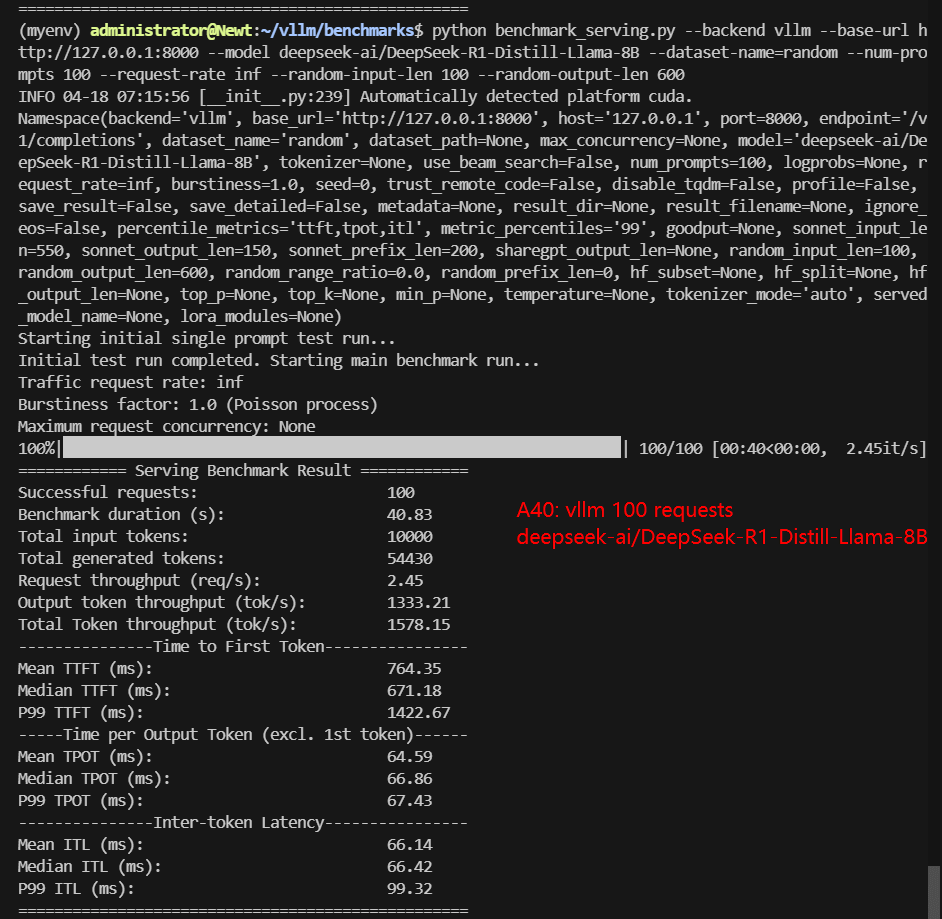
Data Item Explanation in the Table:
- Quantization: The number of quantization bits. This test uses 16 bits, a full-blooded model.
- Size(GB): Model size in GB.
- Backend: The inference backend used. In this test, vLLM is used.
- Successful Requests: The number of requests processed.
- Benchmark duration(s): The total time to complete all requests.
- Total input tokens: The total number of input tokens across all requests.
- Total generated tokens: The total number of output tokens generated across all requests.
- Request (req/s): The number of requests processed per second.
- Input (tokens/s): The number of input tokens processed per second.
- Output (tokens/s): The number of output tokens generated per second.
- Total Throughput (tokens/s): The total number of tokens processed per second (input + output).
- Median TTFT(ms): The time from when the request is made to when the first token is received, in milliseconds. A lower TTFT means that the user is able to get a response faster.
- P99 TTFT (ms): The 99th percentile Time to First Token, representing the worst-case latency for 99% of requests—lower is better to ensure consistent performance.
- Median TPOT(ms): The time required to generate each output token, in milliseconds. A lower TPOT indicates that the system is able to generate a complete response faster.
- P99 TPOT (ms): The 99th percentile Time Per Output Token, showing the worst-case delay in token generation—lower is better to minimize response variability.
- Median Eval Rate(tokens/s): The number of tokens evaluated per second per user. A high evaluation rate indicates that the system is able to serve each user efficiently.
- P99 Eval Rate(tokens/s): The number of tokens evaluated per second by the 99th percentile user represents the worst user experience.
A40 Hosting, A40 vLLM benchmark, A40 LLM performance, A40 vs A6000 for LLMs, Best LLM for A40 GPU, vLLM A40 throughput, A40 14B model benchmark, A40 thermal management LLMs, DeepSeek vs Llama-3 A40, Qwen2.5 A40 speed test, Gemma-3 A40 compatibility